Ready, set, sequence – The evolution and future of NGS
In this guest editorial from INTEGRA Biosciences discover how NGS has transformed genomic research since its initial development, broadening our understanding of genetic variation and gene expression
30 Sept 2024
DNA sequencing is a cornerstone of modern life sciences, providing detailed genetic information that is essential for advancing the fields of medicine, agriculture and biotechnology, alongside many others. For example, sequencing is central to identifying the mutations that cause genetic conditions, understanding the underlying mechanisms of these diseases, and developing effective, personalized treatments with reduced side effects. Sequencing the genomes of viruses, bacteria and other pathogens also enhances our understanding of how they evolve, spread and develop resistance to drugs, enabling better control and prevention strategies, including the development of mRNA vaccines.
The technique is clearly vital for accelerating discovery in multiple areas of research, so it may come as a surprise that DNA sequencing has a relatively short history. The first major breakthrough was achieved in 1977 when two methods – Maxam-Gilbert and Sanger sequencing – were developed1,2. Sanger sequencing proved to be the more accurate, robust and easy to use of the two, and so was soon established as the favored approach. Sanger sequencing has come a long way over the last few decades, and the Human Genome Project, which has greatly advanced our understanding of human biology and genetics3, was primarily based on the method.
Entering a new era of genomics
Sanger sequencing represented a huge leap forward for the study of genomics, but has been limited by its inability to sequence more than a single fragment at a time. Increasing demand for more efficient and cost-effective methods in the years that followed highlighted the need for a faster technique able to sequence multiple fragments at the same time. The next breakthrough was pyrosequencing – a technique that is largely based on the detection of pyrophosphate release during DNA synthesis6 – by a group at the Royal Institute of Technology in Stockholm, Sweden, in the late 1990s5. This approach soon led to the development of next generation sequencing (NGS), a high-throughput technique used to sequence millions of DNA or RNA fragments in parallel4.
Pyrosequencing-based technologies were later overtaken by more advanced NGS methods with higher throughput, such as Illumina sequencing, which uses reversible terminator-bound dNTPs that are incorporated into the DNA during synthesis7. The introduction of these second generation sequencing methods dramatically increased speed, scalability and throughput compared to the Sanger method, enabling rapid advancements in genomics.
The third generation of DNA sequencing
The first Illumina sequencing machine was released in 20078, and the technique quickly became the most widely used NGS technology9. This still holds true today but, despite its widespread popularity, Illumina sequencing has its drawbacks. The main disadvantage is that the technique requires a DNA amplification step, which can cause potentially important information – such as the relative abundance of sequences and existence of nucleotide modifications – to be lost10,11. Template amplification also carries the risk of introducing copying errors, and adds significantly to the duration and complexity of sequencing.
Attempts to circumvent the amplification step led to the introduction of long-read NGS methods from Pacific Biosciences (PacBio) in 2011 and Oxford Nanopore Technologies in 20159. PacBio sequencing monitors the incorporation of nucleotides by a polymerase enzyme in real time9, whereas nanopore sequencing uses the base-specific electrical signals generated when single-stranded DNA (ssDNA) molecules pass through nanopores embedded in lipid membranes to determine the sequences of the molecules12. As long-read techniques, PacBio and nanopore sequencing are particularly well suited to dealing with repeating sequences13, outperforming both Sanger and Illumina sequencing14.
An advantage of all three NGS methods over Sanger sequencing is their higher sensitivity; with Sanger sequencing, one chromatogram is generated covering all the DNA molecules in each sample, representing only the dominant DNA sequence present15. This makes analysis easy, but also means that signals generated by minor variants are masked, with variants only detected when they occur in about 15 to 20 percent of the sequences4.
NGS does not produce a single chromatogram, and instead generates millions of reads in parallel, which are then aligned and assembled computationally to reconstruct the entire sequence of the target DNA, providing detailed and sensitive information on the sample's genetic composition. NGS methods in general have a much lower detection limit, and therefore a much higher sensitivity, because they analyze the nucleotide sequence of each molecule or fragment individually15. For example, Illumina sequencing has a detection limit of just one percent4, meaning it can detect rare variants present at very low frequencies within a mixed population of DNA molecules.

Is this the end of Sanger sequencing?
Sanger sequencing has largely been superseded by NGS approaches, but is still in use around the world today, thanks to its particular advantages over more recent methods. For example, it is often used to validate gene variants that have been identified by Illumina sequencing, due to its 99.99 percent accuracy16. Sanger sequencing also remains popular for sequencing a region containing repeats across a small number of samples4, as it can accurately read up to 1000 base pairs without requiring complex data analysis17,18.
Repeats can be determined more easily with Sanger sequencing than the Illumina technique, as the latter typically only generates reads up to 300 bp and requires many short overlapping sequences to be linked together – a task that can be difficult when the repeat sequence is longer than the read sequence4,19. As a result, Sanger sequencing still has a place in the modern lab, for the time being at least.
What’s next for NGS?
NGS has transformed genomic research in the few decades since its initial development, broadening our understanding of genetic variation and gene expression. Its efficiency and ability to process millions of fragments simultaneously have reduced the cost of sequencing an entire human to just a few hundred dollars in the space of 20 years20, making personalized medicine and genetic testing more accessible to the general public. For example, the All of Us research program at the National Institutes of Health (NIH) aims to build a diverse DNA database by sequencing the genome of more than a million US citizens.
NGS has also proven to be enormously versatile, and new research applications are constantly being explored in an array of industries. One thing is for sure, NGS is here to stay, and will continue to play a foundational role in unraveling the mysteries of the genetic world.
Overcoming hurdles for higher throughput
The specific choice of NGS method involves understanding each approach’s unique strengths and weaknesses, and how they could benefit specific sequencing applications. Regardless of the technique chosen though – whether Illumina, PacBio or nanopore sequencing – efficiency and accuracy at every step are key for reliable end results. Fortunately, state-of-the-art technologies are now available to automate NGS library preparation, supporting genomics laboratories of all sizes by streamlining their sequencing workflows and boosting their overall productivity.
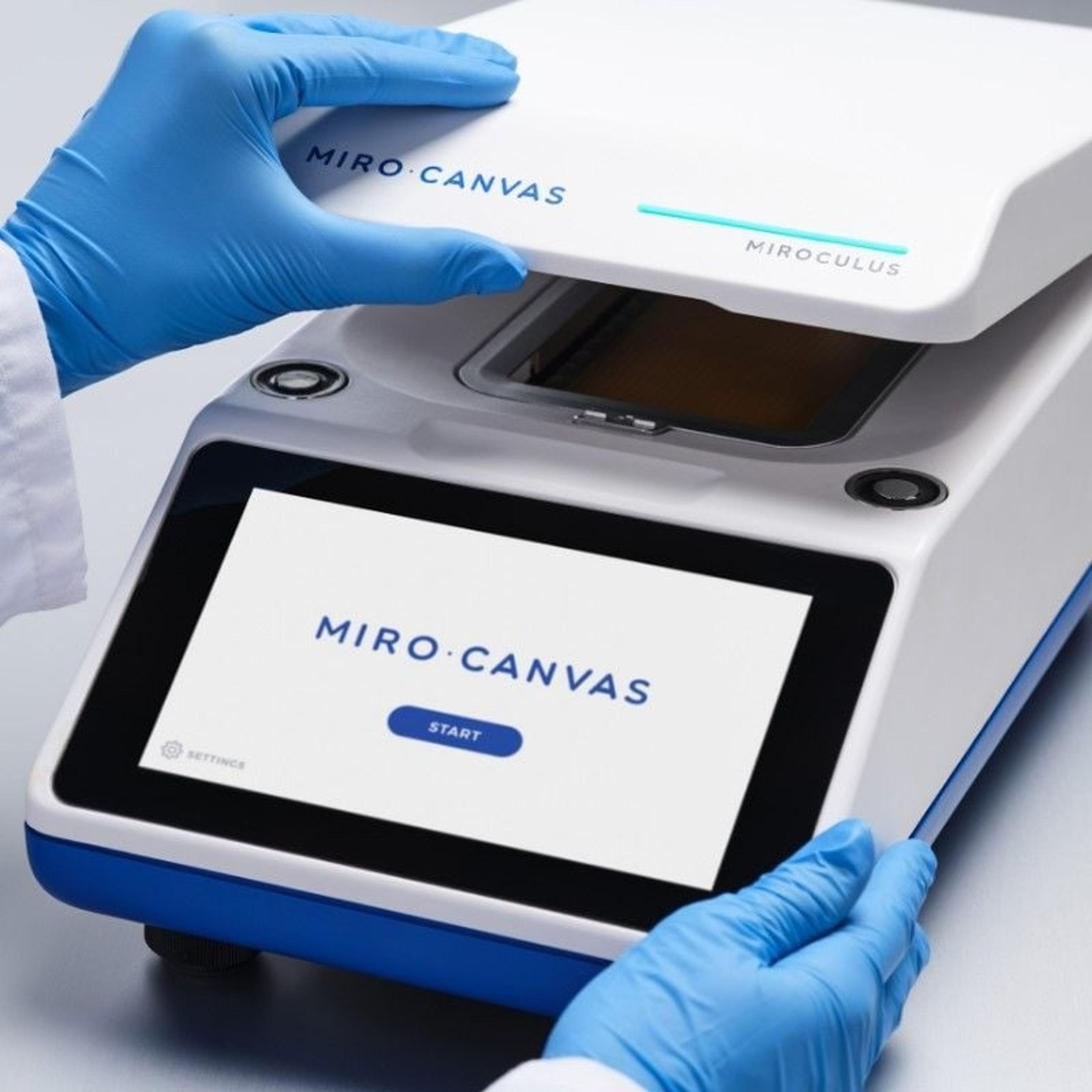
The MIRO CANVAS NGS prep system is a digital microfluidics platform that allows low-throughput NGS library preparation automation for maximum walk-away time. The system integrates all the steps necessary to perform NGS library preparation and hybridization protocols, including thermal cycling and magnetic bead-based operations, and requires only 15 minutes of hands-on interaction in total. The intuitive system uses innovative MIRO cartridges, which reduces reagent consumption by up to 75 percent, and features verified protocols for long-read sequencing, target enrichment and on-demand processing of samples. The platform also monitors reactions during each run, and ensures that all reagents and processes follow the same protocol from day to day or site to site, producing high quality libraries that support consistent, accurate and cost-effective sequencing.
References
1. Maxam A.M., Gilbert W. A new method for sequencing DNA. Proceedings of the National Academy of Sciences. 1977;74(2):560-564. doi:10.1073/pnas.74.2.560
2. Sanger F., Nicklen S., Coulson A.R. DNA sequencing with chain-terminating inhibitors. Proceedings of the National Academy of Sciences. 1977;74(12):5463-5467. doi:10.1073/pnas.74.12.5463
3. National Human Genome Research Institute. Fact Sheet, Human Genome Project . https://www.genome.gov/about-genomics/educational-resources/fact-sheets/human-genome-project.
4. GenScript. Sanger Sequencing vs. Next-Generation Sequencing (NGS). https://www.genscript.com/gene-news/sanger-sequencing-vs-next-generation-sequencing.html.
5. Arney K. DNA sequencing: the next generation. Genetics Unzipped.
6. Mashayekhi F., Ronaghi M. Analysis of read length limiting factors in Pyrosequencing chemistry. Anal Biochem. 2007;363(2):275-287. doi:10.1016/j.ab.2007.02.002
7. Illumina. Introduction to SBS technology. https://www.illumina.com/science/technology/next-generation-sequencing/sequencing-technology.html.
8. Illumina. A Decade in Sequencing . https://emea.illumina.com/science/technology/next-generation-sequencing/illumina-sequencing-history/decade-in-sequencing.html.
9. Shendure J., Balasubramanian S., Church G.M., et al. DNA sequencing at 40: past, present and future. Nature. 2017;550(7676):345-353. doi:10.1038/nature24286
10. Petersen L.M., Martin I.W., Moschetti W.E., Kershaw C.M., Tsongalis G.J. Third-Generation Sequencing in the Clinical Laboratory: Exploring the Advantages and Challenges of Nanopore Sequencing. J Clin Microbiol. 2019;58(1). doi:10.1128/JCM.01315-19
11. Deamer D., Akeson M., Branton D. Three decades of nanopore sequencing. Nat Biotechnol. 2016;34(5):518-524. doi:10.1038/nbt.3423
12. Chow E. Next Generation Sequencing 1: Overview – Eric Chow (UCSF). https://www.youtube.com/watch?v=mI0Fo9kaWqo. Published online November 15, 2018.
13. Birla B. PacBio vs. Oxford Nanopore sequencing. Genohub Blog.
14. Mobley I. Long-read sequencing vs short-read sequencing. Front Line Genomics .
15. Sharma R. NGS versus Sanger Sequencing for Clinical Decisions. Today’s Clinical Lab Trends.
16. ADS. About Sanger Sequencing . https://advancedseq.com/about-sanger-sequencing.
17. Zhang A. How does Next Generation Sequencing work? The Tech Interactive. July 2, 2019. Accessed August 30, 2024. https://www.thetech.org/ask-a-geneticist/articles/2019/sanger-vs-next-gen-sequencing
18. Victoria Wang X., Blades N., Ding J., Sultana R., Parmigiani G. Estimation of sequencing error rates in short reads. BMC Bioinformatics. 2012;13(1):185. doi:10.1186/1471-2105-13-185
19. Gorcenco S., Ilinca A., Almasoudi W., Kafantari E., Lindgren A.G., Puschmann A. New generation genetic testing entering the clinic. Parkinsonism Relat Disord. 2020;73:72-84. doi:10.1016/j.parkreldis.2020.02.015
20. Mullin E. The Era of Fast, Cheap Genome Sequencing Is Here. Wired .
The content for this guest editorial was provided by the team at INTEGRA Biosciences.